Total Downloads: 1,114,656
Month-to-Month Growth: 9.28%
Year-to-Year Growth: 31.32%
Average Daily Downloads: 37,155.2
Month-to-Month Daily Growth: 12.9%
It has been a while since I’ve posted a report, but I figure it’s time.
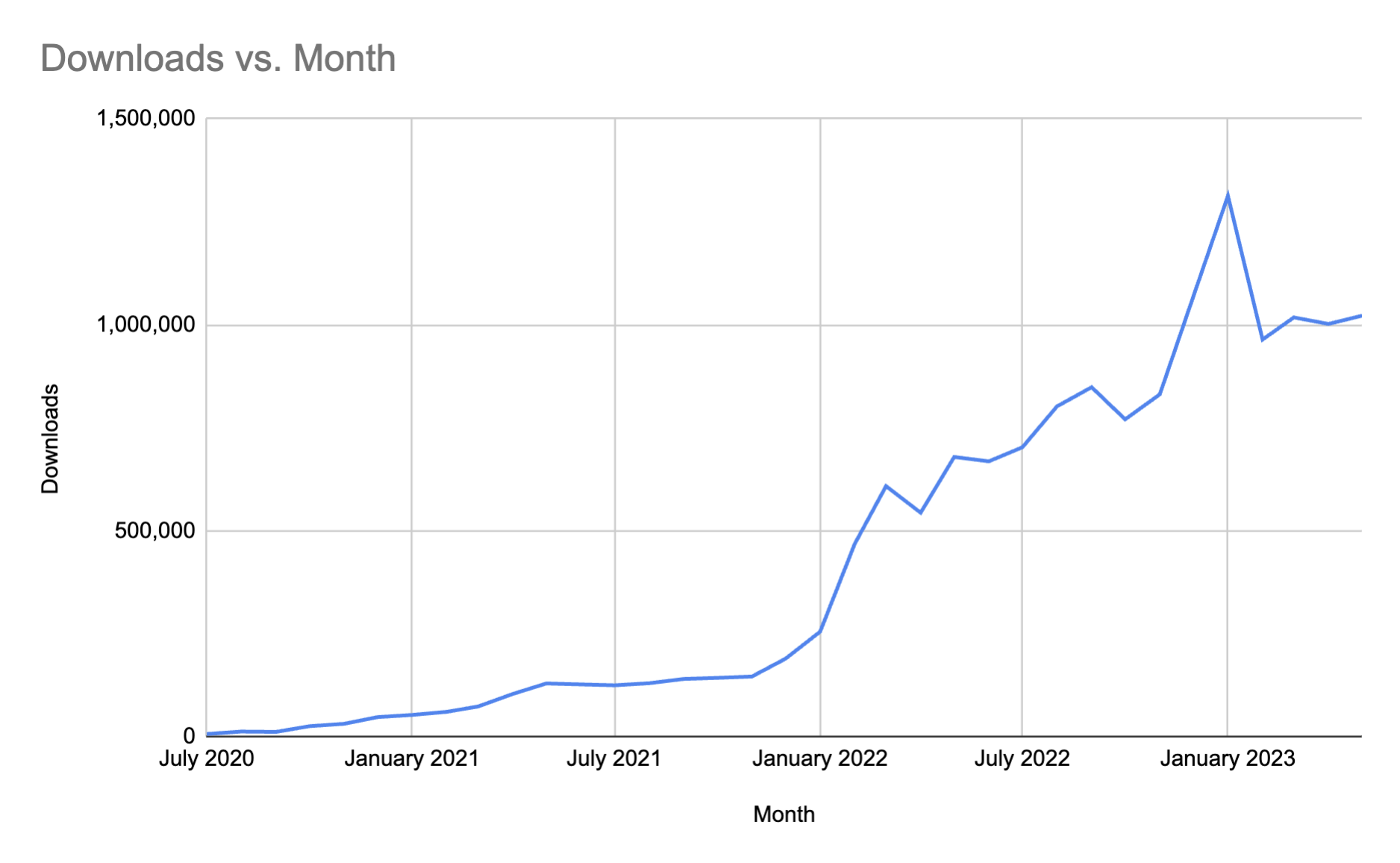
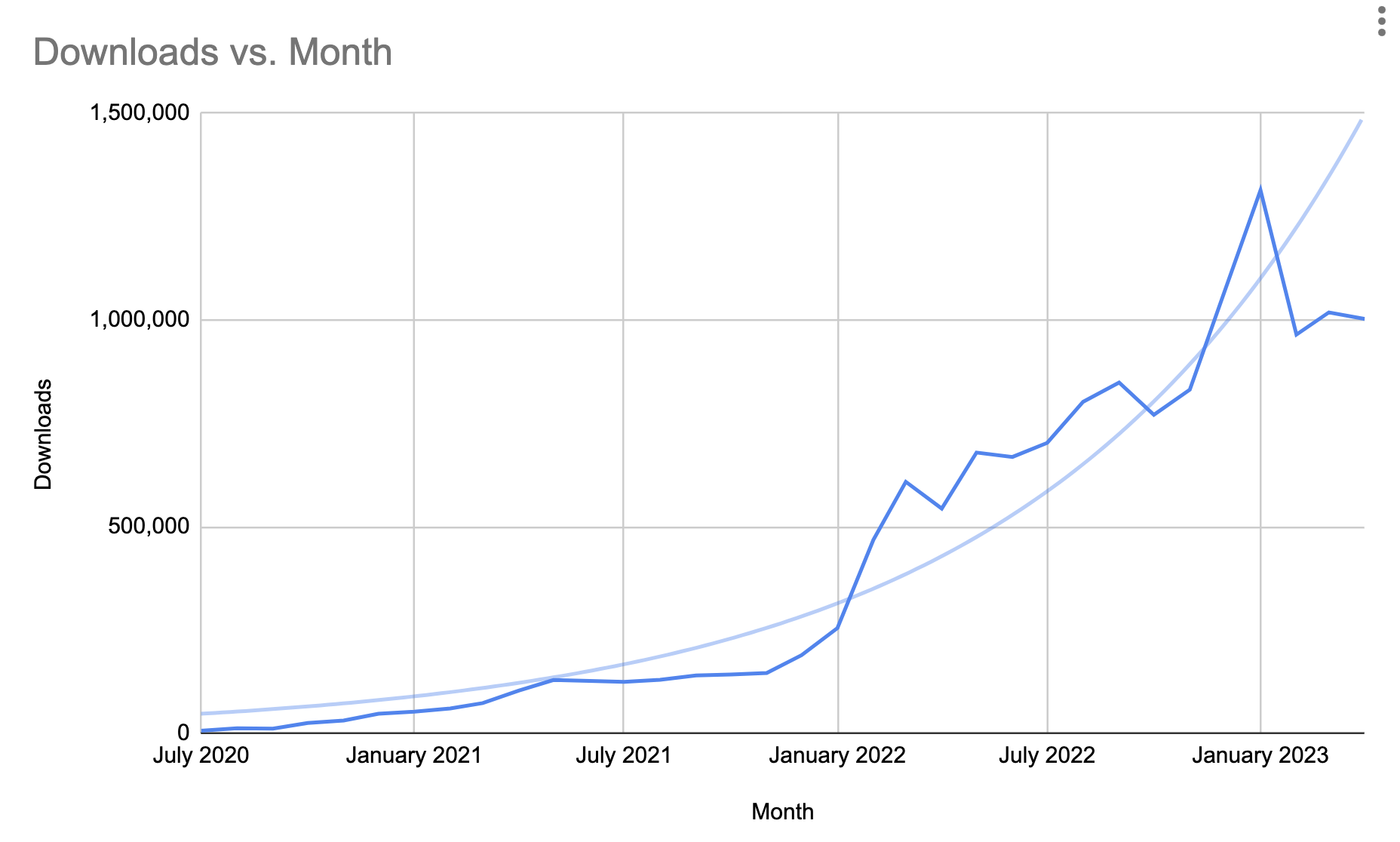
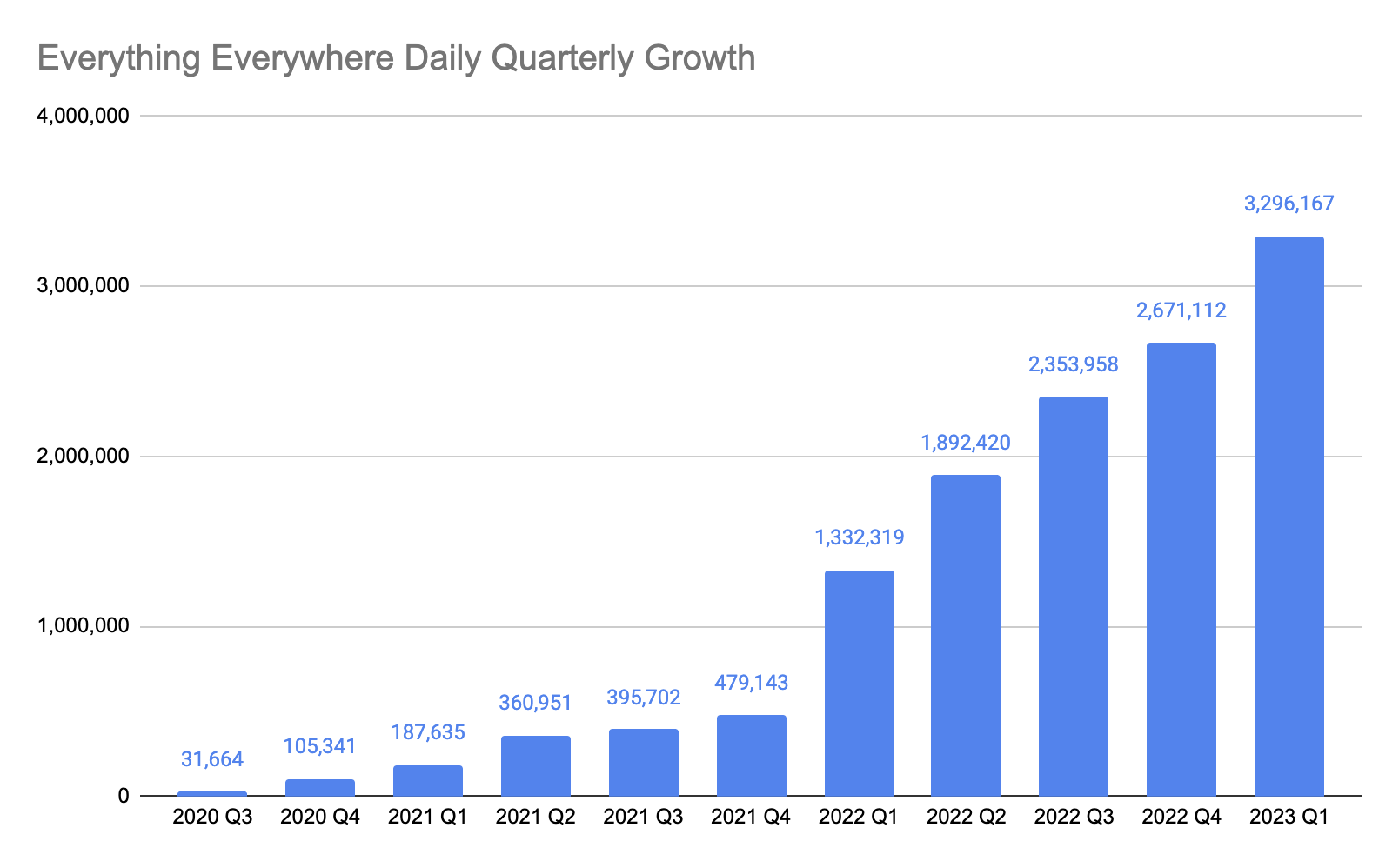
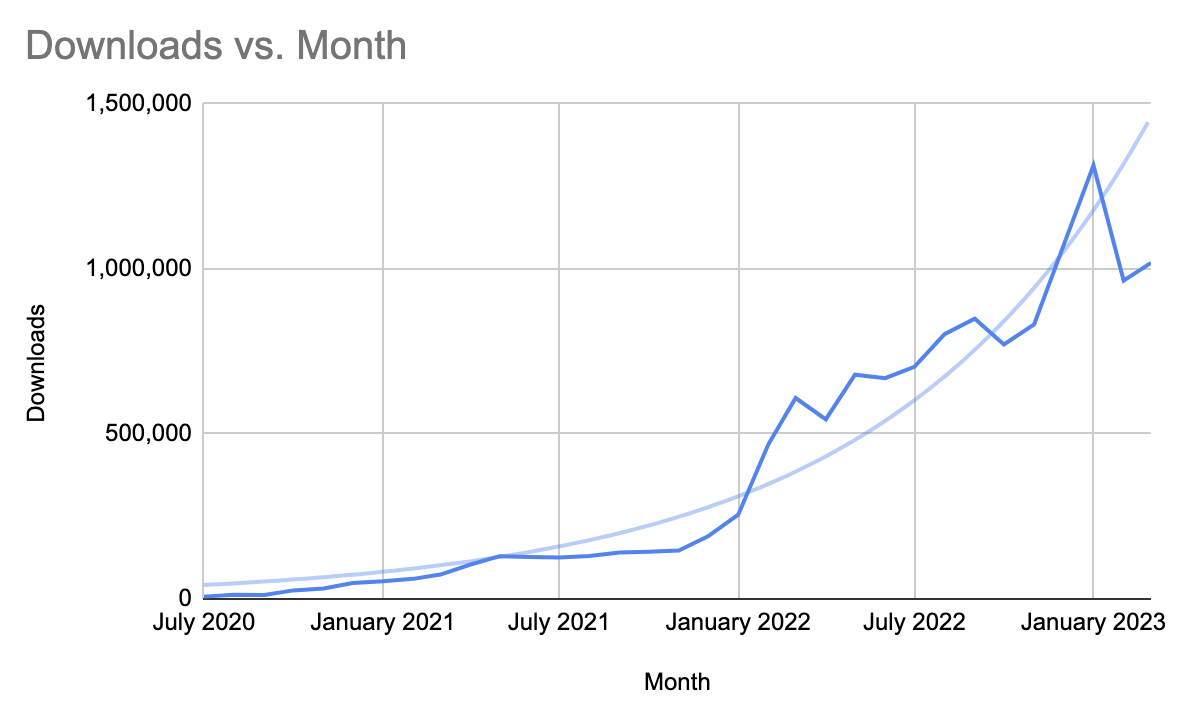
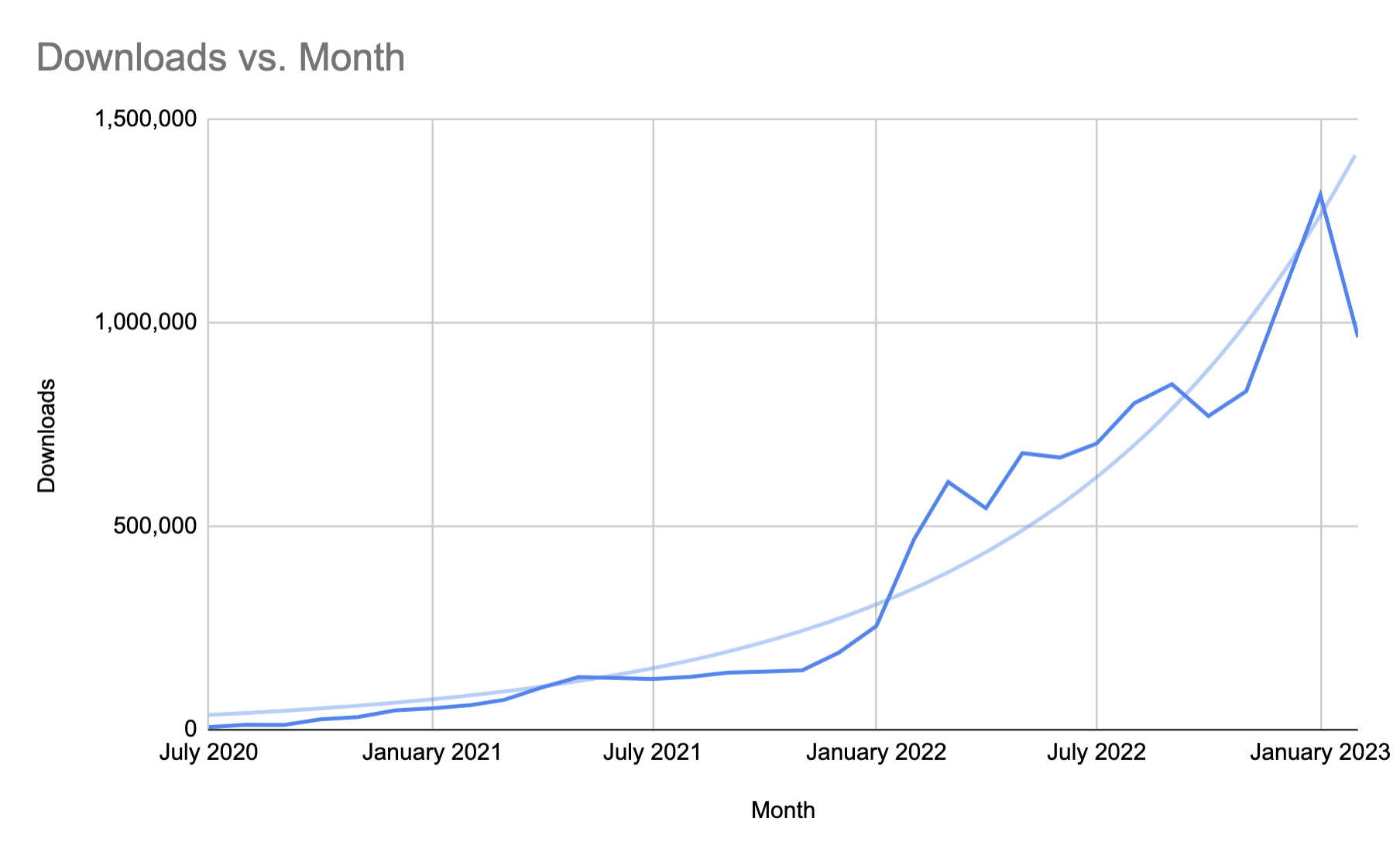
One of the things that skewed my perception of this year is the fact that I had a spike in downloads in January. Take away that spike and I’ve experienced pretty steady growth.
It is also becoming harder to achieve percentage growth in the show once it gets to a certain point. This month, I had over 9% growth. That is actually huge for a show, getting over 1,000,000 downloads.
The increase in the number of downloads I experienced in September is more than most podcasts ever see. Yet, when seen on a graph showing the total history of my podcast, it appears like a blip.
September saw my biggest single day for downloads. On September 19, I had 64,393 downloads. It is hard to predict when those days will happen, but I’ll certain take it.
This summer, I spent a lot of time trying to buy promotions and feed drops on smaller podcasts with similar audiences. I’ve mostly given up on that. It is simply too frustrating.
Most smaller podcasts have no business sense and it takes a lot of time for something that wont really move the needle.
I’ll probably have to invest more in doing fewer promotions on larger podcasts.
One thing I did do, and I have no idea exactly how much this has affected my downloads, in improved my SEO.
I’ve started using a tool called Voxalyze. It is basically an SEO tool for podcasts to see how you appear on Apple and Spotify in search results.
It turns out my podcast does very well in terms of search visibility.

My show currently ranks #43 in the world on Apple Podcasts for all podcasts in terms of visibility. That is out of 2,624,164 on Apple Podcasts.
I’m ranked #233 on Spotify, but Spotify also claims almost twice the number of podcasts as Apple.
Either way, that puts me in the top 0.001 percent of podcasts world wide, at least for this metric.
This is primarily due to the fact that I’ve published over 1,100 episodes on a wide variety of topics.
One of my biggest challenges going forward is finding help.
Creating Everything Everywhere Daily has been a solo effort since I started the show in 2020. Simply writing and getting a show out the door every day is a challenge and doesn’t leave me with a lot of time to do other things that I should be doing to promote the show.
Right now, I’d just be happy to find an assistant to take some of the daily tasks off my hands, like creating episode artwork, website admin, and social media.
I have no solution. This is just a rant.